Blog
Writings on Bayesian inference, machine learning, and AI alignment.

Risky optimisation
AI risk viewed through the lens of optimisation.
October 18, 2023
Viewing AI risk through the lens of optimisation provides intuitions for why AI risk is a problem and for what potential solutions must achieve.

AI alignment
The enormous problem facing humanity.
May 14, 2023
My views on the importance and difficulty of the AI alignment problem.
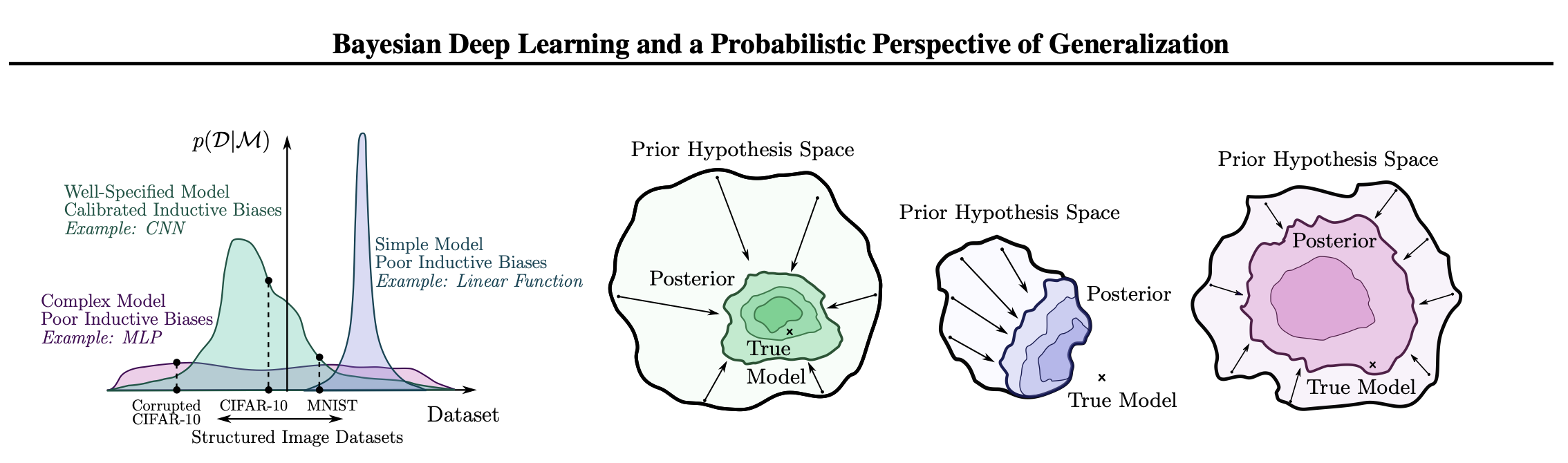
Priors and generalisation
Implicit priors in deep learning methods
May 12, 2023
A look at the role of priors in deep learning methods.

From Bayesian inference to modern machine learning
How Bayesian inference is hiding in your non-Bayesian models
April 6, 2021
A tour from prescriptive Bayesianism to modern statistical machine learning.
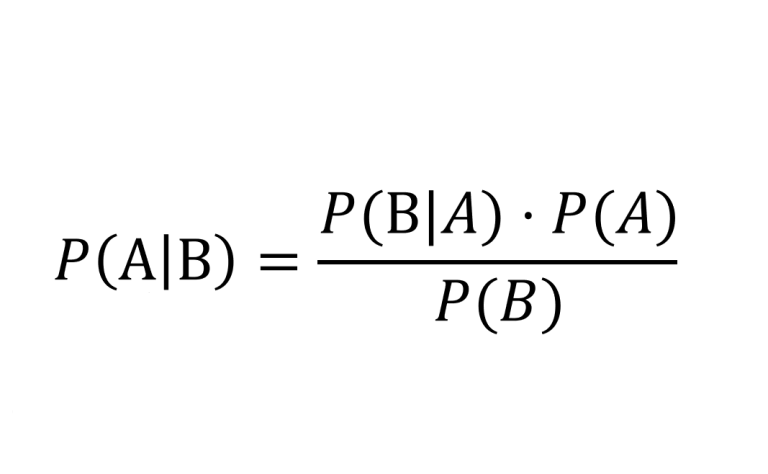
Everything but commentary
Have you heard the good word of our lord and saviour Bayes?
March 2, 2021
A look at the objective Bayesian prescription for reasoning under uncertainty.